A biblioteca Numba pode ser usada para compilar código Python que opera em arrays para código de máquina com excelente performance. Podemos utilizar Numba também para compilar funções nopython para rodar em GPUs NVIDIA. Dependendo do tipo de processamento a ser executado, a utilização de GPUs pode ser muito vantajosa e resultar em ganhos de desempenho de 10-100 vezes em relação à codigo otimizado rodando em CPUs.
Uma CPU moderna possui, em geral, entre 2 e 8 cores. Ao executar um programa multi-thread (ou usando multiprocessing, como já fizemos antes), cada core da CPU executa uma thread (ou processo) de maneira completamente independente dos outros processadores. GPUs, por sua vez, possuem centenas ou milhares de cores que estão organizados de maneira hierárquica e não são independentes uns dos outros. Os cores de uma GPU estão agrupados em Streaming Processes (SMs), que funcionam em um modo batizado de SIMT (Single Instruction, Multiple Threads). Basicamente, cada SM funciona de maneira independente dos outros SMs e contém um certo número de cores que trabalham de maneira sincronizada. A mesma instrução é executada em todos os cores de um SM, mas utilizando dados diferentes. Por esta razão, a NVIDIA batizou este tipo de processamento de data-parallel processing.
Para executar uma função (kernel) na GPU é necessário dividir o problema a ser tradato em um grid de blocos de threads, como na figura abaixo. Cada bloco executará em um SM seu conjunto de threads, fazendo com que seja possível executar vários blocos ao mesmo tempo. Dentro de um bloco, todas as threads executam em paralelo, mas de modo sincronizado. Um máximo de 1024 threads podem existir em cada bloco e cada thread tem acesso tanto à sua posição no bloco como à posição de seu bloco no grid.
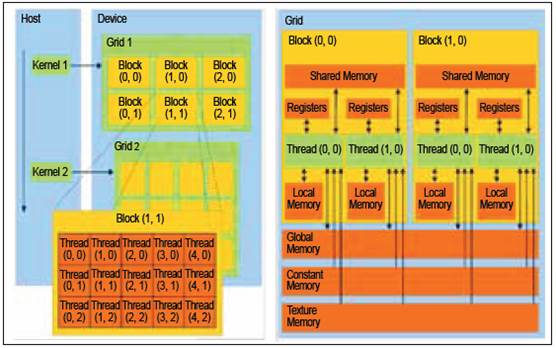
Para, por exemplo, processar uma imagem de tamanho $512\times 512$, poderíamos criar um grid de tamanho $16\times16$ em que cada bloco contém 32 threads. Cada thread determina o valor de um pixel. O grid faz o papel de um duplo for que percorre todos os pontos da imagem.
Como podemos ver na imagem (1), uma outra diferença desta nova arquitetura é que a GPU possui sua própria memória, que pode estar inclusive fisicamente separada da memória da CPU. Antes de lançar um kernel é necessário copiar os dados da memória da CPU para a GPU e após o processamento é necessário copiar o resultado de volta. Logo, processar um volume pequeno de dados pode não ser vantajoso, pois a maior parte do tempo será gasta copiando os dados.
Infelizmente, não podemos executar código Python arbitrário em GPUs. Ao contrário da utilização de Numba em CPUs, que gera código em modo objeto se não for possível otimizar todas as operações, a compilação para GPUs só pode ser feita em modo nopython (veja algumas das restrições no post anterior sobre Numba). Usaremos como exemplo uma implementação do gradiente morfológico feita em GPU.
Primeiramente, é necessário instalar os drivers mais atuais da GPU usada (disponíveis aqui) e o CUDA SDK. Um pacote binário com o CUDA SDK chamado cudatoolkit pode ser instalado via conda.
import numba.cuda
import numpy as np
import math
@numba.cuda.jit
def grad_morpho(img, out):
pi, pj = numba.cuda.grid(2)
if pi > 2 and pi < img.shape[0]-4 and pj > 2 and pj < img.shape[1]-4:
minv = 255; maxv = 0
for i in range(-3, 4):
for j in range(-3, 4):
pix = img[pi+i, pj+j]
if pix < minv:
minv = pix
if pix > maxv:
maxv = pix
out[pi, pj] = maxv - minv
def versao_numba_gpu(img):
out = img.copy()
img2 = img.copy()
threads_per_block = (16, 16)
nblocks = (math.ceil(img.shape[0] / threads_per_block[0]),
math.ceil(img.shape[1] / threads_per_block[1]))
grad_morpho[nblocks, threads_per_block](img2, out)
return out
Na função call_grad_morpho definimos o número de threads por bloco e o número de blocos no grid e chamamos a função grad_morho, que é executada na GPU de maneira paralela. Isto fica explícito no código ao notarmos que não existe um duplo for que percorre os pontos da imagem. Cada que thread executa grad_morpho sabe a sua dentro de seu bloco e sua posição absoluta no grid. Uma maneira conveniente de obter esta posição é chamar a fução numba.cuda.grid(ndim), que calcula os índices para um grid de ndim=1,2,3 dimensões.
Outro ponto importante é que nem sempre o grid coincide com as dimensões dos dados, então é muito importante checar se o ponto pi, pj que recebemos não ultrapassa as dimensões das imagens tratadas.
Como comparação, colocamos abaixo o código otimizado Cython que fizemos anteriormente (colado abaixo) e executamos ambas funções em uma imagem tamanho $4096\times4096$.
%load_ext cython
%%cython
import cython
@cython.boundscheck(False)
@cython.nonecheck(False)
cdef void morpho_gradient_cython(long[:,:] img, long[:,:] out, int pi, int pj) nogil:
cdef int i, j, minv, maxv
minv = 255
maxv = 0
for i in range(-3, 4):
for j in range(-3, 4):
if img[pi+i, pj+j] < minv:
minv = img[pi+i, pj+j]
if img[pi+i, pj+j] > maxv:
maxv = img[pi+i, pj+j]
out[pi, pj] = maxv - minv
@cython.boundscheck(False)
@cython.nonecheck(False)
@cython.cdivision(True)
cpdef void versao_cython(long[:,:] img, long[:,:] out) nogil:
cdef int i, j, k, w, h
h = img.shape[0]; w = img.shape[1]
for i in range(3, h-4):
for j in range(3, w-4):
morpho_gradient_cython(img, out, i, j)
import scipy
import scipy.misc
import numpy as np
img_temp = scipy.misc.lena()
img2 = np.c_[img_temp, img_temp]
img3 = np.r_[img2, img2]
img4 = np.c_[img3, img3]
img = np.r_[img4, img4]
img = np.r_[img, img]
img = np.c_[img, img]
out = img.copy()
print('Versão Cython')
%timeit versao_cython(img, out)
print('Versão Numba GPU')
%timeit versao_numba_gpu(img)
versao_cython(img, out)
out2 = versao_numba_gpu(img)
print('Imagens iguais?', np.all(out == out2))
Como podemos ver, a diferença entre os tempos de execução é muito grande. Utilizar Numba para executar código em GPU pode ser muito eficiente se o problem for altamente paralelizável.
Nenhum comentário:
Postar um comentário